

Understanding Greek naming traditions
Greek names are getting more attention these days as more Greek citizens bank internationally. Why? Intelligent name matching is fundamental to verify identities in many high-stakes verticals including financial compliance, border security, and customer management. So, as several Rosette customers in the financial services industry experienced a surge of Greek customers, they need tools to quickly and accurately verify and screen names in Greek script.
The release of Rosette 1.10.0 added support for matching between Greek names in Greek script (and between Greek names written in Greek and their English transliterations), as well as the transliteration of person, organization, and location names from Greek to Latin script. While the framework of our intelligent fuzzy name matching system spans many languages, there are always language-specific idiosyncrasies to research, annotate, and accommodate to maintain the unparalleled accuracy and speed our customers demand.
Here are some unique aspects of Greek culture and language that can affect Greek text processing and more specifically, name matching and transliteration.
Most Greek names are very old, based upon the names of the Orthodox saints or the names of famous ancient Greek leaders and gods. Because of this, Greek names have less variation than countries, like the U.S., that place less import on tradition and culture when naming children.
Greek families typically pass down the same names through the generations. Parents are expected to follow a standard pattern of passing on family names to their children:
- The first born child is named after the paternal grandfather
- The second child is named after the maternal grandfather
- The third born child is named after the paternal grandmother
- The fourth child is named after the maternal grandmother
- The parents can choose the name of further children
If the gender of the child is different from their namesake, the name is altered to have the proper gendered ending. For example, the firstborn granddaughter of Γιώργος (Giórgos) would be named Γεωργία (Georgía). In large families, these rules can mean that many cousins share exactly the same name, or very similar names if they are different genders.
This custom is particularly common among older generations. As average family sizes shrink however, parents who want to placate both sides of the family or prefer modern names may give their children two first names. For example, if a couple only has two children, they may name their firstborn after both grandfathers, Νικόλαος Κώστας (Nicholas Kostas) and their second Μαρία Ελένη (Maria Eleni), after both grandmothers. Individuals with two first names may go by both names, only one name or the other, or a portmanteau of both names, for example, Maria Eleni can become “Marilena.”
It is important to note that these are two-word first names, not a first and middle name as is common in English-speaking countries. Greek people traditionally do not have middle names. A non-native speaker may enter a Greek name into a database incorrectly:
| First | Middle | Last | |
| Incorrect | Nicholas | Kostas | Demetriou |
| Correct | Nicholas Kostas | Demetriou |
When selecting a name search tool, make sure your solution can search and match names across structured fields to ensure potential matches are not missed. This point is particularly vital in Greek as well as other languages where a single name part can consist of multiple tokens, such as Spanish where last names are often more than one word long.
Differentiating name gender
Naturally, the frequency of popular names and similarity among family names presents a challenge to many common name matching methods. The more popular a name, the more likely it is to result in false positives when searching a database by name.
Names are commonly searched using phonetic keys like Soundex, Metaphone, and Double Metaphone. Known as the Common Key method, phonetic algorithms generate keys that represent how a name sounds, in particular, its consonants.
| Name | Double Metaphone Key |
| Χρήστος Δημητρίου (Chrístos Dimitríou) | KRST TMTR |
| Χριστίνα Δημητρίου (Christína Dimitríou) | KRST TMTR |
Another method for matching names is the Edit Distance method, which looks at how many character changes it takes to get from one name to another — useful for dealing with typos
Again, because male and female Greek names can be extremely similar, this method may not be reliable. Μάρια Παπαδοπούλου (Mária Papadopoulou) and Μάριος Παπαδόπουλος (Mários Papadopoulos) have an edit distance of only 3, which most systems would consider a very probable match, but would not be considered a match between Greek names.
When working with names written in Greek script, the end of the name is a strong indicator of gender. For example, the Greek letter sigma found at the end of a name (-ς) is highly indicative of a male name (or the genitive case of a feminine name, more on that later). Similarly, the letter eta found at the end of a name (-η) will almost always indicate that the name is female.
| 1-gram Suffixes | female | male | unisex |
| ή | 10 | 0 | 0 |
| α | 41 | 0 | 30 |
| η | 17 | 0 | 3 |
| ι | 0 | 0 | 49 |
| ς | 2 | 131 | 22 |
Caption: a selection of Greek letters and the frequency with which they are found at the end of the a list of 467 gender-identified Greek names. So, 41 female Greek names in the sample ended with ‘α’, whereas there were 0 male names that ended with ‘α’, and 30 unisex names ended with ‘α’.
If you expect to process Greek names, make sure your solution has been trained to identify gender and penalize the match score when the gender of two names doesn’t match, even if the names look quite similar according to other matching methods.
Transliterating Greek script
As with any non-Latin script language, natural language processing methods must be built with the native script in mind, and trained on data written in that script.
Greek transliteration is not a simple one-to-one, letter-by-letter process. The Greek alphabet has twenty-four characters as opposed to the twenty-six found in the Latin alphabet. Simplistic systems can inaccurately transliterate Greek names to Latin script or vice versa, multiplying the chance of an error when the transliterated name is searched or matched.

For example, several Latin letters are often mapped to two letters in Greek (and vice-versa):
- b → mu pi
- j → tau zeta
- d → nu tau
Additionally, written Greek includes many diacritics. These are marks near or above letters that indicate stress, pronunciation, and more. In order to be accurately processed by linguistic algorithms — such as name matching and search applications — Greek text (or any non-Latin text) must first be “normalized,” a process of reducing text to a standard, Unicode-compatible form. Normalization can include:
- Replacing contiguous runs of trailing and leading whitespaces with a single space
- Performing case unification (transforming to all upper or lower case letters)
- Replacing punctuation with spaces
- Removing language- and type-specific stop words (words which appear so frequently in the language as to be unhelpful)
- Stripping away extraneous diacritics that do not affect the meaning of the text
While diacritics are mostly applicable to spoken language, sometimes pronunciation can change the meaning of a word. For example, in English the noun “record” (\ ˈre-kərd als \) stresses the first syllable. Contrastingly, the verb form (\ ri-ˈkȯrd \) places its emphasis on the second half of the word. This small change alters the meaning from a grooved disk from which music can be played to the physical activity of saving audio to a disk or file.
For example, the presence of a smooth breathing mark as opposed to a rough breathing mark indicates whether an “h” sound should be pronounced:
| Polytonic orthography | Meaning | Pronunciation |
| Smooth breathing mark: ᾿h | No “h” in the pronunciation | “eh” |
| Rough breathing mark: ῾h | Pronounce the “h” | “heh” |
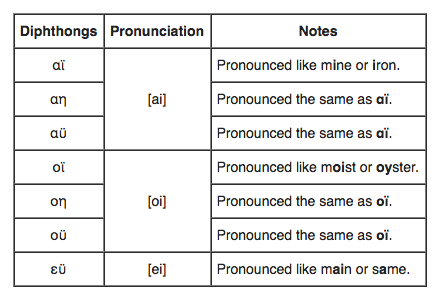
For Greek text, one diacritic in particular, the diaeresis, must be retained. A diaeresis is a mark found over the second vowel of a diphthong to indicate that each of the two vowels of which the diphthong is comprised should be pronounced as a separate syllable. Diphthongs are certain vowel+vowel combinations that result in a single sound (as in feat).
Let’s consider an example specific to person names. Take the name Ραϋμόνδος (Rafmóndos or Raymond). The diaeresis in the diphthong αϋ is pronounced like the letter “i” in the English word “mine.” Without the diaeresis however, αυ sounds like av.
As a rule of thumb, natural language processing is most successful when performed on text in its native language with a system that was trained on that language. This rule applies to all text analytics processes, not just name matching. When looking for your text analytics solution, search for tools that have multilingual training, not just one model applied to hundreds of languages.
Consistent case normalization
Another challenge for processing Greek text is correctly normalizing cases. The same word has multiple forms depending on its function in a sentence. In English, a noun is nominative when it is the subject of a sentence (“I”), accusative when it is the direct object (“me”), and genitive when it is the possessive “my”). Modern Greek also has the vocative case for nouns that are the addressee of a statement.
The nominative form of a word is what you find in a dictionary (called a “lemma”), and the ideal form for normalization. Basic machine translation normalizes all nouns to whichever case it sees most frequently in its training data — which is typically either nominative or accusative. This failure to normalize to a single case results in messy data and processing errors.
For example, recall we said earlier that many male Greek names end with the letter sigma. This is only true if all the names in your database are in their nominative form. The genitive form of many female names also ends in sigma. If your database contains names in many different cases, you cannot refine your results with language-specific linguistic knowledge.
Again, when searching for the right Greek natural language processing solution, make sure your provider has thoroughly and accurately annotated training data so that words are normalized correctly and consistently.


